SPSS怎么进行数据变量合并?比如在收集地区数据时,需要不同地区的人员分开收集,而在数据汇总的阶段,就需要使用到数据合并的功能将这些不同来源的数据合并汇总。下面小编就带着大家学习一下怎么进行变量数据的合并吧!
操作方法:
一、打开需合并的数据
变量合并的作用是将不同数据文件中,相同个案的不同变量数据进行合并。比如数据A包含了年龄、性别等数据,而数据B包含了地区、收入等数据,而这些数据都是来自同一批个案,就可以通过变量合并数据。
首先,在SPSS中分别打开两个需要合并的数据文件。
 图1:打开数据
图1:打开数据如图2所示,可以看杯盘狼藉拼音:bēi pán láng jí释义:狼藉象狼窝里的草那样散乱。杯子盘子乱七八糟地放着。形容吃喝以后桌面杂乱的样子。出处:《史记·滑稽列传》日暮酒阑,合尊促坐,男女同席,履舄交错,杯盘狠藉。”示例:这桌子微醺,那桌子半酣,~,言语喧哗。★清·李绿园《歧路灯》第八十八回到,两个数据文件中存在着账号、性别、客单价三个相同变量,以及Area、地区、来源、点击页面数四个不同变量,其中地区与Area实际为同一个变量,但命名方式不同。
 图2:对比变量差异
图2:对比变量差异二、使用变量合并功能
接着,如图3所示,依次打开数据-合并文件-添加变量,针对数据文件的异同点进行变量合并。
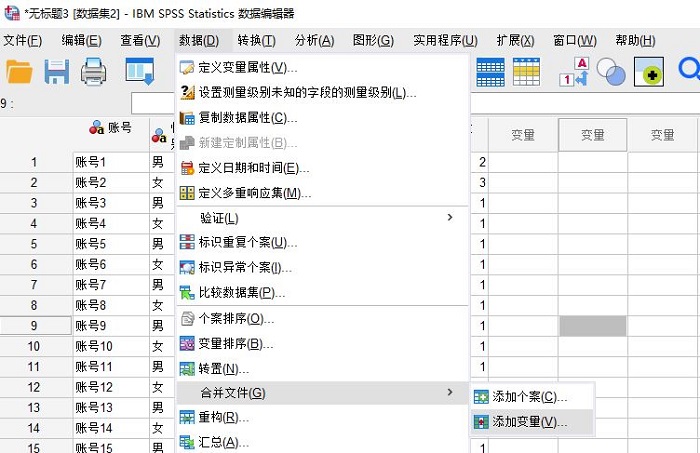 图3:变量合并功能
图3:变量合并功能由于当前打开的是数据集2,因此最终的数据会合并到数据集2中。如图4所示,以数据集2为基础,与之前已打开的数据集3进行合并。
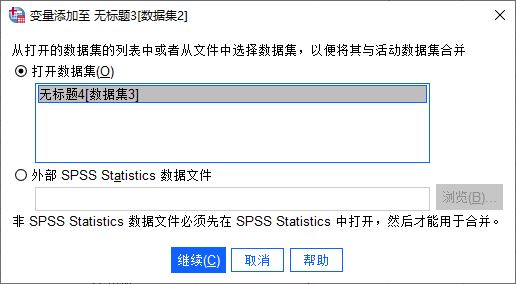 图4:指定合并的数据文件
图4:指定合并的数据文件接着,如图5所示,打开变量选项卡,进行变量合并的设置。
其中,变量括号中含+的是数据集2中不包含的变量,而含*的是数据集2中包含的变量。设置的变量含义如下:
排除的变量,即两个数据文件中存在差异的,但在合并数据过程中需要剔除的变量。
包含的变量,即两个数据文件中存在差异的,但在合并数据过程中需要保留的变量。
键变量,即两个数据文件同时包含的变量。
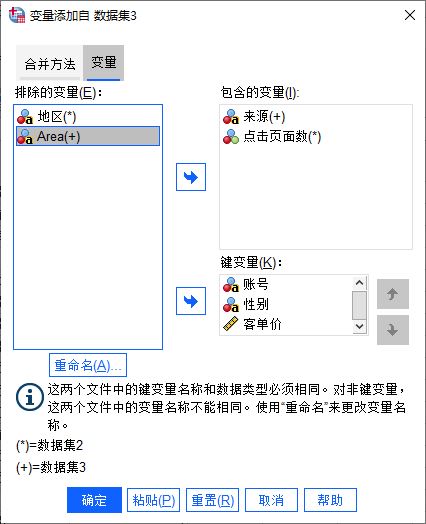 图5:设置变量的合并方式
图5:设置变量的合并方式由于变量“地区”与“Area”实际为同一变量,可将其中一个添加为“包含的变量”,另外,还可以通过重命名的方法,将“Area”重命名为“地区”。
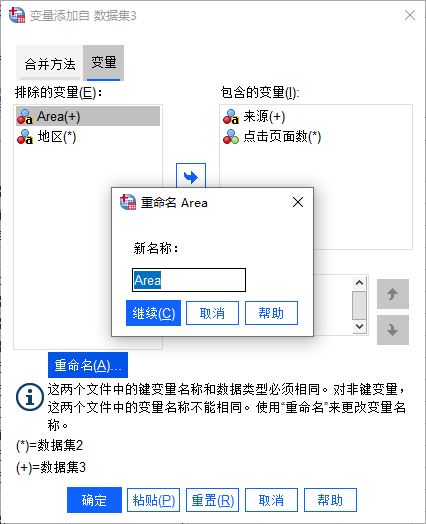 图6:重命名变量
图6:重命名变量如图6所示,可以看到“Area”已重命名为“地区”,将其添加为“包含的变量”。
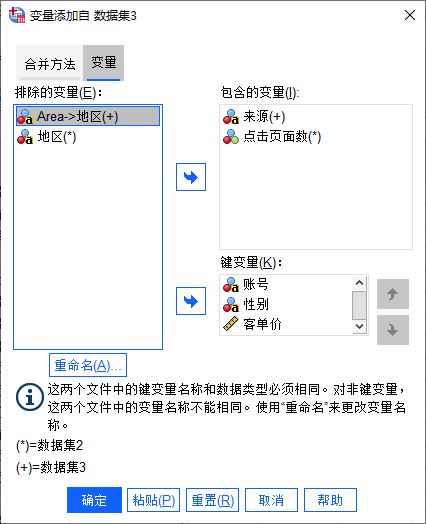 图7:完成变量的重命名
图7:完成变量的重命名如图7所示,在包含的变量中,“Area”变量已经重命名为“地区”变量。当然,我们也可以直接使用数据集2中包含的“地区”变量。
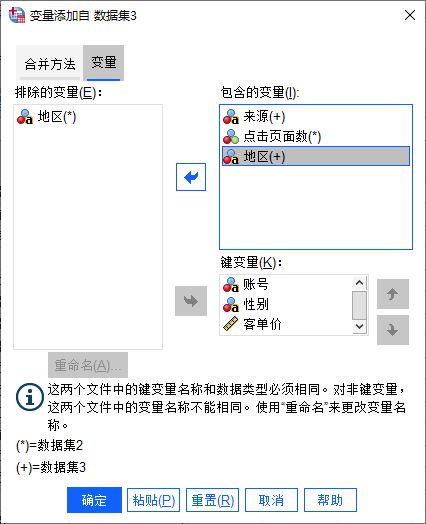 图8:添加重命名后的变量
图8:添加重命名后的变量完成以上操作后,如图8所示,可以看到,变量已经合并完成。后续,可对数据作进一步的整理,如排序等。
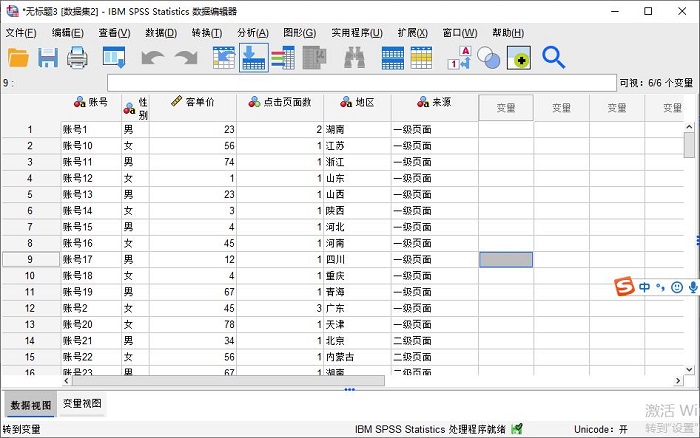 图9:完成变量的合并
图9:完成变量的合并以上就是SPSS数据合并中的变量合并操作演示。
SPSS怎么进行数据变量合并?SPSS数据进行变量合并教程日落西山龙马精黔驴技穷神21. 亲情不仅是孟郊的“慈母手中线,游子身上衣”的长长牵挂,它也是王维“独在异乡为异客,每逢佳节倍思亲”的深沉感叹,是苏轼“但愿人长久,千里共婵娟”的美好祝愿,是辛弃疾“最喜小儿无赖,溪头卧剥莲蓬”的天伦之乐……11 旅游与交通224.日出江花红胜火,春来江水绿如蓝。《忆江南》 到此因念,绣阁轻抛,浪萍难驻。叹后约、丁宁竟何据。惨离怀、空恨岁晚归期阻。凝泪眼、杳杳神京路。断鸿声远长天暮。133刘长卿:秋日登吴公台上寺远眺SPSS,变量数据怎么合并A monopoly occurs when one company alone offers a particular food or service and therefore controls the market and price for it.
- Win10系统如何开启体验共享 Win10系统体验共享开启教程
- Win10占用互联网带宽的方式及解决办法
- 联想Win10防火墙怎么关闭 联想Win10防火墙关闭方法介绍
- Win10的wifi功能不见了只有飞行模式怎么办?
- Win10每次打开应用都要弹出是否允许更改怎么办?
- 如何实现mac与windows之间的文件共享?
- Win10怎么将所有文件夹统一视图?
- Win11麦克风有回音怎么消除 Win11麦克风回声怎么调
- Windows11任务栏消失了怎么办 Windows11任务栏消失了解决方法
- Win11麦克风无法找到输入设备怎么办?
- Windows11只有百兆网速怎么解除限速?
- Windows10怎么不满屏 Windows10屏幕不满屏解决方法
- Windows10缩放全屏在哪 Windows10怎么调缩放全屏
- Win10提示无法保存ip设置请检查一个或多个文件设置并重试怎么解决?
- Windows10系统备份错误怎么办 Windows10系统备份错误解决方法
- Windows10未激活分辨率调不了 Windows10未激活分辨率怎么调
- Win10应用程序无法正常启动0xc0000142错误怎么解决?
- Win11怎么看用了多少流量?Win11查看数据使用量方法
- Win11更新后进入安全模式闪屏怎么办
- Win10怎么永久关闭自动更新?Win10彻底关闭自动更新的方法
- Win11如何运行安卓app?Win11运行安卓app教程
- Win11能录屏吗?Win11自带录屏怎么用不了?
- Win10开始菜单点击无反应?五种方法帮你解决
- 电脑如何重装Win10系统?U盘重装Win10系统教程
- Win11触摸板手势自定义设置方法
- 水电费物业费管理系统软件
- 华硕主板ASUS PcProbe华硕系统诊断家最新
- 华硕主板ASUS PcProbe华硕系统诊断家最新
- 华硕主板Ai Booster超频工具最新
- 惠普Pavilion Elite HPE-515cn台式电脑Intel Rapid Storage Technology驱动程序更新
- 华硕主板ASUS PC Probe II华硕系统诊断家最新
- 惠普PavilionElite HPE-515cn台式电脑IDT 高保真声卡出厂预装驱动程序
- 技嘉i-Cool工具最新
- 惠普 Pavilion Elite HPE-515cn台式电脑 Intel Rapid Storage Technology 驱动程序更新
- 微星主板最新PC Alert 4程序
- 奇迹时代4社会特性所需点数修改MOD v3.6
- 隔离区丧尸末日生存CE修改器 v1.36
- 艾尔登法环黄金律法拉达冈MOD v2.29
- 星露谷物语Lnh的休闲农场MOD v3.46
- 奇迹时代4勤勉4级主城招冰龙和凤凰MOD v2.52
- 艾尔登法环武器添加元素特效MOD v3.72
- 艾尔登法环罗亚果实制作王之卢恩MOD v3.35
- 奇迹时代4可选择的单位外观转换MOD v3.53
- 磁带妖怪修改器 v1.0
- 我的世界实体渲染机制优化V1.18.2MOD v2.53
- Miss
- miss
- misshapen
- missile
- missing
- missing link
- missing person
- mission
- missionary
- missionary position
- 佛教哲学(方立天文集第4卷)
- 魏晋南北朝佛教(方立天文集第1卷)
- 中国古代哲学(下方立天文集第6卷)
- 中国古代哲学(上方立天文集第5卷)
- 励耘书屋问学记(增订本史学家陈垣的治学)
- 共同犯罪论(第2版)/陈兴良刑法研究专著系列/中国当代法学家文库
- 量守庐学记(黄侃的生平和学术)
- 量守庐学记续编(黄侃的生平和学术)
- 金融经济学(教育部推荐教材)/金融学研究生核心教材系列
- 蒙文通学记(增补本蒙文通生平和学术)
- [BT下载][恋爱潜伏][第12集][WEB-MKV/0.22G][国语配音/中文字幕][4K-2160P][H265][流媒体][DeePTV]
- [BT下载][扫毒风暴][第18集][WEB-MP4/4.80G][国语配音/中文字幕][4K-2160P][60帧率][H265][流媒体][ColorTV]
- [BT下载][活死喵之夜][第03集][WEB-MKV/1.35G][简繁英字幕][1080P][流媒体][DeePTV]
- [BT下载][一饭封神][第01集][WEB-MKV/0.27G][国语配音/中文字幕][1080P][H265][流媒体][DeePTV]
- [BT下载][一饭封神][第01集][WEB-MKV/1.27G][国语配音/中文字幕][4K-2160P][H265][流媒体][DeePTV]
- [BT下载][扫毒风暴][第20集][WEB-MP4/4.81G][国语配音/中文字幕][4K-2160P][60帧率][H265][流媒体][ColorTV]
- [BT下载][扫毒风暴][第20集][WEB-MP4/1.53G][国语配音/中文字幕][4K-2160P][60帧率][H265][流媒体][ColorTV]
- [BT下载][扫毒风暴][第20集][WEB-MP4/1.33G][国语配音/中文字幕][4K-2160P][H265][流媒体][DeePTV]
- [BT下载][扫毒风暴][第20集][WEB-MP4/1.33G][国语配音/中文字幕][4K-2160P][H265][流媒体][ColorTV]
- [BT下载][扫毒风暴][第20集][WEB-MP4/3.25G][国语配音/中文字幕][4K-2160P][杜比视界版本][H265][流媒体][D