
Puppeteer是一款专业的 Node.js 库,相当于一个可以用来操控Chrome的API,它可以用到的场景很多,如它具有强大的爬虫功能,有点类似于PhantomJS,用来在网站抓取内容非常不错,有需要的朋友欢迎使用。
Puppeteer核心功能:
利用网页生成PDF、图片
爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染)
可以从网站抓取内容
自动化表单提交、UI测试、键盘输入等
帮你创建一个最新的自动化测试环境(chrome),可以直接在此运行测试用例
捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题
Puppeteer 0.13改变如下:
Chroium 64.0.3264.0 (r515411)
browser.pages 可用于访问 Chromium 中的所有页面,包括由 window.open 创建的页面。 (32398d1)
browser.close 可用于关闭 Chromium (2b79514)
Puppeteer爬虫教学:
使用puppeteer.launch()运行puppeteer,他会return一个promise,使用then方法获取browser实例,Browser API猛击这里
拿到browser实例后,通过browser.newPage()方法,可以得到一个page实例, 猛戳 Page API
使用page.goto()方法,跳转至ES6标准入门
在page.evaluate()方法中注册回调函数,并分析dom结构,从下图可以进行详细分析,并通过
document.querySelectorAll('ol li a')拿到文章的所有链接
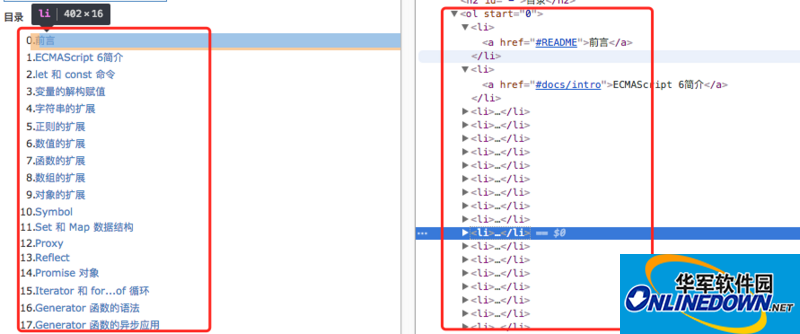
拿到所有链接之后,依次爬取各个页面(也可以promise all同时抓取多个页面),使用page.pdf()方法打印当前页面
核心代码如下:
puppeteer.launch().then(async browser => {
let page = await browser.newPage();
await page.goto('http://es6.ruanyifeng.com/#README');
await timeout(2000);
let aTags = await page.evaluate(() => {
let as = [...document.querySelectorAll('ol li a')];
return as.map((a) =>{
return {
href: a.href.trim(),
name: a.text
}
});
});
await page.pdf({path: `./es6-pdf/${aTags[0].name}.pdf`});
page.close()
// 这里也可以使用promise all,但cpu可能吃紧,谨慎操作
for (var i = 1; i < aTags.length; i++) {
page = await browser.newPage()
var a = aTags[i];
await page.goto(a.href);
await timeout(2000);
await page.pdf({path: `./es6-pdf/${a.name}.pdf`});
page.close();
}
browser.close();
});
- 学校卫生检查表
- 物品采购申请表
- 物流运输报价表
- 物流运费价格表
- 物流价格查询表
- 物料平衡表
- 卫生检查表
- 危险化学品安全检查表
- 天地华宇物流价格表
- 体格检查表
- 特种设备安全检查表
- 数据统计表模板
- 数据分析统计表
- 做错之题管理
- 九中答题卡阅卷系统
- Free Burn MP3-CD
- iStonsoft PDF to ePub Converter
- 锡育英语听力制作软件
- 全能王PDF转换器
- 小学语文同步课堂
- 视力检查表
- Batch PPT to TXT Converter
- 海权少儿加减乘除练习
- Boxoft Free FLV to WMV Converter
- 食堂卫生检查表
- 仁王2幻影紫狼面具MOD v3.6
- 鬼谷八荒三国绝色步练师立绘服饰MOD v3.66
- 怪物猎人世界冰原克苏鲁聚合物笛子MOD v1.19
- 七日杀挑战玩法无法制作MOD v3.73
- 求生之路2艾达王旗袍替换2代黑妹MOD v1.80
- 七日杀管理员技能点MOD v3.83
- 模拟人生4v领女性美丽印花连衣裙MOD v1.72
- 环世界技能升级提示v1.2MOD v2.84
- 我的世界成就完成自动截图MOD v1.31
- 上古卷轴5重制版进攻盾牌MOD v1.54
- photographer
- photographic
- photographic memory
- photography
- photojournalism
- photon
- photo opportunity
- photosensitive
- photo session
- Photostat
- 旅游学(理论与案例5版旅游管理英文原版精品教材)
- 中国产能过剩的政治经济学分析
- 关中唐十八陵(精)
- 阳光穿透岁月的墙/名家名篇系列
- 微电影创作技巧(附光盘)
- 编程原本/计算机科学经典译丛
- 时光知味岁月留香/名家名篇系列
- 中国区域发展的制度研究--近邻效应制度空间与机会窗口
- 新时代的中国国防(2019年7月)
- 7-8岁叛逆期妈妈情商课
- [BT下载][长风渡][第37-38集][WEB-MKV/3.00G][国语音轨/简繁英字幕][4K-2160P][H265][BlackTV] 剧集 2023 大陆 剧情 连载
- [BT下载][间谍教室 第二季][第01集][WEB-MP4/0.35G][中文字幕][1080P][Huawei] 剧集 2023 日本 动画 连载
- [BT下载][隼消防团][第01集][WEB-MKV/1.46G][中文字幕][1080P][Huawei] 剧集 2023 日本 剧情 连载
- [BT下载][青莲剑仙传][第27集][WEB-MP4/0.14G][国语配音/中文字幕][1080P][Huawei] 剧集 2023 大陆 动画 连载
- [BT下载][风月变][第01-06集][WEB-MKV/2.99G][国语配音/中文字幕][1080P][Huawei] 剧集 2023 大陆 其它 连载
- [BT下载][风月变][第07集][WEB-MKV/0.41G][国语配音/中文字幕][1080P][Huawei] 剧集 2023 大陆 其它 连载
- [BT下载][麻烦请你先告白][全24集][WEB-MP4/3.08G][国语配音/中文字幕][1080P][Huawei] 剧集 2023 大陆 剧情 打包
- [BT下载][麻烦请你先告白][全24集][WEB-MP4/3.58G][国语配音/中文字幕][4K-2160P][H265][Huawei] 剧集 2023 大陆 剧情 打包
- [BT下载][麻烦请你先告白][全24集][WEB-MP4/1.80G][国语配音/中文字幕][1080P][H265][BlackTV] 剧集 2023 大陆 剧情 打包
- [BT下载][麻烦请你先告白][全24集][WEB-MP4/3.94G][国语配音/中文字幕][4K-2160P][H265][BlackTV] 剧集 2023 大陆 剧情 打包
- 《原神》金蔷薇种子位置说明 金蔷薇种子在哪
- 微信AI攻克与女孩聊天重大难题 大规模语言模型WeLM上线
- 《宝石研物语伊恩之石》开服公告汇总
- 《宝石研物语:伊恩之石》首周幻之石及许愿券获取攻略
- 《女鬼桥开魂路》全程不躲柜子难点讲解
- 《装机模拟器2》玩法及设定介绍 装机模拟器2好玩吗
- 烟草局拟出台电子烟寄递限量新规
- 《火炬之光无限》附魔与赋能系统介绍
- 《火炬之光无限》狂人贫血火旋风斩开荒BD分享
- 《羊了个羊》10月14日通关攻略 10.14第二关攻略