SPSS中怎么进行快速聚类分析?许多用户在使用spss数据分析软件的时候都会遇到一些问题,最近就有不少小伙伴在询问spss怎么快速聚类分析,下面小编就为大家讲解一下吧!
操作方法:
一、方法概述
聚类分析是将研究对象按照一定的标准进行分类的方法,分类结果是每一组的对象都具有较高的相似度,组间的对象具有较大的差异。
这类分析方法多用于对于数据样本没有特定的分类依据的情况,IBM SPSS Statistics 会通过对数据的观察为用户做出较为完善的分类。
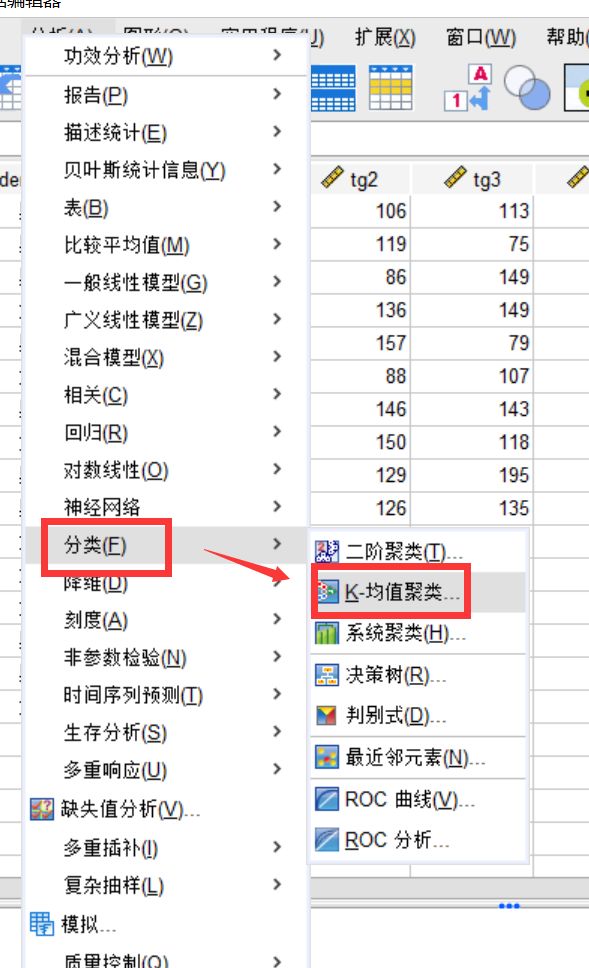 图1:功能位置
图1:功能位置快速聚类是聚类分析的一种,使用到的功能在“分析”——“分类”中的“K-均值聚类”。
二、案例分享
1、样本数据
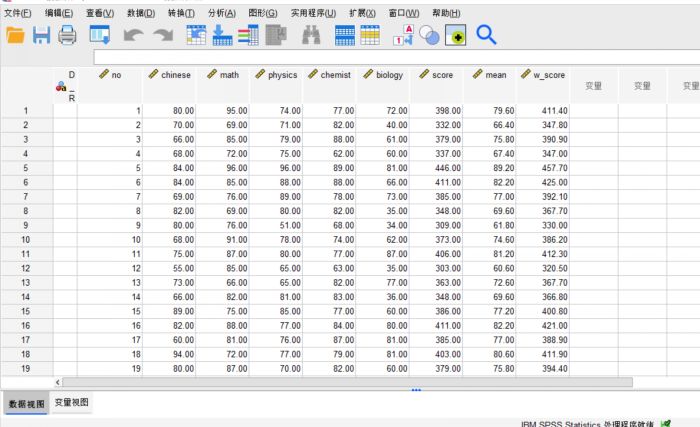 图2:样本数据
图2:样本数据我们这里选择的数据样本是一部分学生的各科期末成绩,使用快速聚类方法可以分析各个学生成绩分布的差异和共性。
2、变量设置
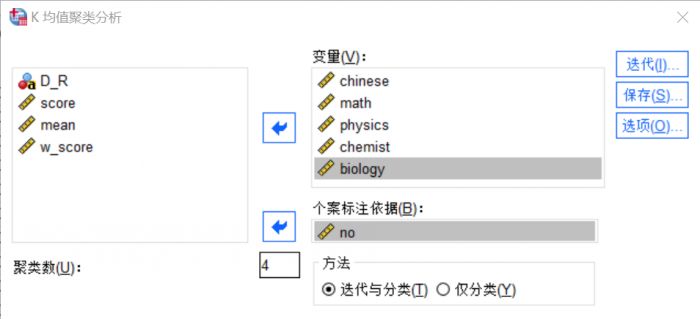 图3:变量设置
图3:变量设置我们将学生的所有单科成绩作为分析变量,移入到“变量”窗口中,将学生的编号变量移入到下侧的“个案标记依据”窗口。
聚类数设置的是分类的数目,这个需要根据数据样本的特点来设置,我们这里设置为4类。
聚类方法有两类,即迭代和分类,前者较为复杂,会在分析过程中不断移动凝聚点,后者则始终使用初始凝聚点,我们选择两类都有的第一种分析方法。
3、聚类中心
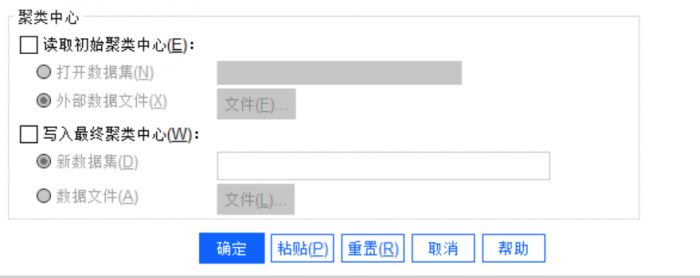 图4:聚类中心
图4:聚类中心用户可以选择从外部文件或数据文件中写入或读取聚类中心,本案例中我们不使用这个功能。
4、迭代设置
 图5:迭代设置
图5:迭代设置我们可以设置迭代的终止条件,即到达设定的最大值后将停止迭代分析,输出聚类分析结果。
收敛性标准设置的是凝聚点改变的最大距离小于初始凝聚点的比例,小于设定值时,也会停止迭代,输出结果。
使用运行均值表示每次观测后都重新计算凝聚点,这些设置保持默认即可。
5、保存
 图6:保存新变量
图6:保存新变量这是用来设置保存形式的,勾选“聚类成员”将保存SPSS的分类结果,勾选“与聚类中心的距离”将保存观测值和所属类别的欧氏距离,我们不做设置。
6、选项
 图7:选项设置
图7:选项设置这个对话框设置的是输出的统计量和个案缺失处理方法,勾选“初始聚类中心”和“每个个案的聚类信息”。
7、结果输出
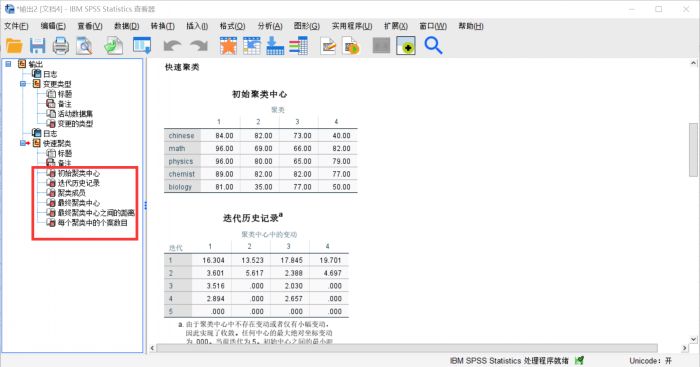 图8:聚类结果
图8:聚类结果在输出日志中可以看到,这些学生根据他们的单科成绩被分成了四类,SPSS输出了多个表格,包括初始聚类中心、迭代历史记录、聚类成员、最终聚类中心、最终聚类中心之间的距离和每个聚类中的个案数目,完整详细,可信度较高。
18. 还有一部分失恋的人会检讨不足总结经验教训,为下一次展开行动前将自己做好质的转变。恋爱叫人不寂寞,等你以此为功德去造福人类了,也算是现代都市公德一件了。
SPSS中怎么进行快速聚类分析?SPSS数据快速聚类分析教程想得厉害眉清目秀(浮想联翩同甘共苦)34. 爱在过境,缘分不停,向来情深,奈何缘浅。窗外小雨淅淅沥沥,我最后听见了下雨的声音,我的世界被吵醒,窗台上的滴落的雨滴,轻敲着悲哀,凄美而动听。眼睛在下雨,心却为你打伞,一颗潮湿的心,一份滴水的痴情!倘若听见我哽咽的声音,请捂住耳朵,让我一向孤傲;倘若听看到我心碎的裂痕,请闭上眼睛,让我一向伤悲……30.考虑到诸多因素 take many factors into account/ consideration129.盛名之下,其实难副。 渐吹尽,枝头香絮,是处人家,绿深门户。远浦萦回,暮帆零乱向何许?026元结:贼退示官吏并序SPSS,数据快速聚类分析48、Never hit a man when he is down.
- 云闪付怎么用-云闪付转账的步骤
- Aegisub(x32)怎么打开样式管理器-Aegisub(x32)教程
- Aegisub(x32)怎么设置样式助手-Aegisub(x32)教程
- Aegisub(x32)怎么打开assdraw3-Aegisub(x32)教程
- Adobe After Effects CS6新建图层快捷键是什么-快捷键介绍
- Adobe After Effects CS6透明度快捷键是什么-透明度快捷键介绍
- Adobe After Effects CS6时间轴快捷键有哪些-快捷键介绍
- Adobe After Effects CS6全屏预览快捷键是什么-快捷键介绍
- Adobe After Effects CS6旋转快捷键是什么-旋转快捷键介绍
- Adobe After Effects CS4播放快捷键是什么-播放快捷键介绍
- Adobe After Effects CS4不透明度快捷键是什么-快捷键介绍
- Adobe After Effects CS4撤回快捷键是什么-撤回快捷键介绍
- Adobe After Effects CS4打包快捷键是什么-打包的图层快捷键介绍
- Adobe After Effects CS4倒放快捷键是什么-倒放快捷键介绍
- Adobe Illustrator CS6裁剪快捷键是什么-裁剪快捷键介绍
- Adobe Illustrator CS6标尺快捷键是什么-标尺快捷键介绍
- Adobe Illustrator CS6编组快捷键是什么-编组快捷键介绍
- Adobe Illustrator cc2020蒙版快捷键是什么-蒙版快捷键介绍
- Adobe Illustrator cc2020描边快捷键是什么-描边快捷键介绍
- Adobe Illustrator cc2020取消轮廓快捷键是什么-快捷键介绍
- Adobe Illustrator cc2020锁定参考线快捷键是什么-快捷键介绍
- Adobe Illustrator CS6创建轮廓快捷键是什么-创建轮廓快捷键介绍
- Adobe Illustrator CS6复制画板快捷键是什么-复制画板快捷键介绍
- Adobe Illustrator CC 2019网格快捷键是什么-网格快捷键介绍
- Aegisub(x32)怎么打开字体搜集器-Aegisub(x32)教程
- Simple Comic
- Simple Comic
- Stykz
- Color Converter
- Web Help Desk For Mac
- SmartBackup For Mac
- French Verb Games
- Photo to Movie
- NuGen Visualizer
- XPilotPanel
- 模拟人生4女性皮质夹克MOD v1.21
- 辐射4朱莉安娜Looksmenu预设MOD v3.10
- 星露谷物语复古式界面MOD v2.4
- 逆水寒刘亦菲血河女捏脸数据 v2.3
- 饥荒新的船型MOD v1.80
- DNF男枪手模型2016夏日套改天2鸟人冥枭震日补丁 v2.4
- 逆水寒鹿晗铁衣捏脸数据 v2.4
- 上古卷轴5天际重制版静弘MOD v2.3
- 只狼影逝二度帅气炎龙侠MOD v1.6
- 星露谷物语时间增长及停止MOD v2.3
- nightshirt
- nightspot
- nightstand
- nightstick
- night-time
- night watchman
- nightwear
- nigiri
- nihilism
- nil
- 沙漠里的藏宝洞(文化遗产在中国)(精)
- 站稳课堂--教学过程的理性研究
- 量子异质结构理论与计算/信息光子学与光通信系列丛书
- 旧邦维新(清末新政与直隶地方政治变革)
- 基诺山--太阳的手印/云南八个人口较少民族发展丛书
- 中国金融安全评论(第3卷)
- 米小圈上学记一年级(套装共4册)小学生课外阅读书籍注音版 [7-10岁]
- 米小圈上学记(三年级)
- 读懂双循环新发展格局:助力“十四五”高质量发展
- 暮天归思/余秋雨文学十卷
- [BT下载][七夕之国][第04-05集][WEB-MKV/3.66G][简繁英字幕][1080P][Disney+][流媒体][ZeroTV]
- [BT下载][七夕之国][第04-05集][WEB-MKV/10.49G][简繁英字幕][4K-2160P][杜比视界版本][H265][Disney+][流媒体][ZeroTV]
- [BT下载][七夕之国][第04-05集][WEB-MKV/9.16G][简繁英字幕][4K-2160P][HDR版本][H265][Disney+][流媒体][ZeroTV]
- [BT下载][香肠聚会:食托邦 第一季][全8集][WEB-MKV/11.24G][简繁英字幕][1080P][流媒体][ZeroTV]
- [BT下载][异世界自杀小队][第05集][WEB-MKV/0.98G][简繁英字幕][1080P][流媒体][ZeroTV]
- [BT下载][异世界自杀小队][第05集][WEB-MP4/0.37G][中文字幕][1080P][流媒体][ZeroTV]
- [BT下载][黑袍纠察队 第四季][第07集][WEB-MKV/3.90G][简繁英字幕][1080P][流媒体][ZeroTV]
- [BT下载][黑袍纠察队 第四季][第07集][WEB-MKV/6.61G][简繁英字幕][4K-2160P][H265][流媒体][ZeroTV]
- [BT下载][黑袍纠察队 第四季][第07集][WEB-MKV/6.54G][简繁英字幕][4K-2160P][HDR版本][H265][流媒体][ZeroTV]
- [BT下载][卡戴珊家族 第五季][第08集][WEB-MKV/2.02G][简繁英字幕][1080P][Disney+][流媒体][ZeroTV]