|
海-OCR是一款批量图片转文字软件,通过OCR文字识别技术从图片中提取文字。用户只需要导入图片文件,使用起来非常简单。该软件是基于PaddleOCR的脱机OCR模块开发的。它可以训练模型,支持修改PaddleOCR参数和添加不同的语言模型。这个软件可以识别多种语言。当然,如果你想使用后面提到的这些功能,你必须会开发。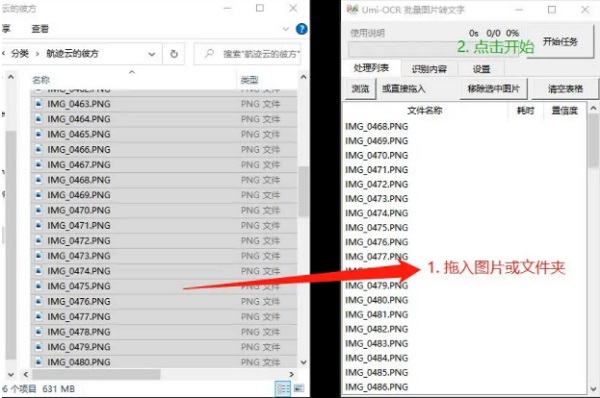 软件介绍这个“海-OCR”与其他OCR软件的不同之处在于,它主要是批量识别普通图片和识别文本内容进行导出,而且它还有支持忽略指定区域的特殊功能,比如屏蔽视频右上角的水印和游戏的UI内容。对于某些场景来说,批量识别图片比逐个识别效率要高得多。用起来也很简单。批量拖动需要识别的图片。 软件介绍这个“海-OCR”与其他OCR软件的不同之处在于,它主要是批量识别普通图片和识别文本内容进行导出,而且它还有支持忽略指定区域的特殊功能,比如屏蔽视频右上角的水印和游戏的UI内容。对于某些场景来说,批量识别图片比逐个识别效率要高得多。用起来也很简单。批量拖动需要识别的图片。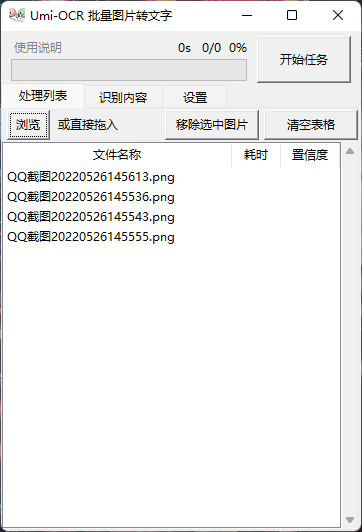 接下来点击设置,可以设置勾选的识别内容写入本地文件。您可以选择txt文本或Markdown格式,并选择输出目录。 接下来点击设置,可以设置勾选的识别内容写入本地文件。您可以选择txt文本或Markdown格式,并选择输出目录。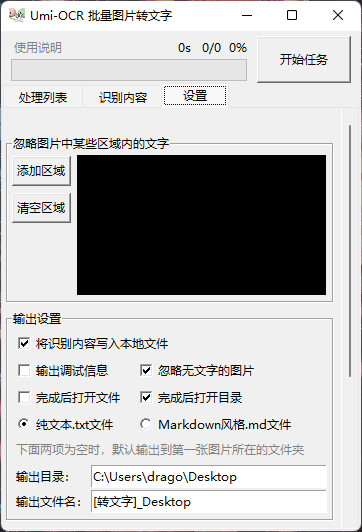 如果您识别的图像中有不需要的东西,比如水印,可以点击添加区域功能,然后选择不需要识别的区域。 如果您识别的图像中有不需要的东西,比如水印,可以点击添加区域功能,然后选择不需要识别的区域。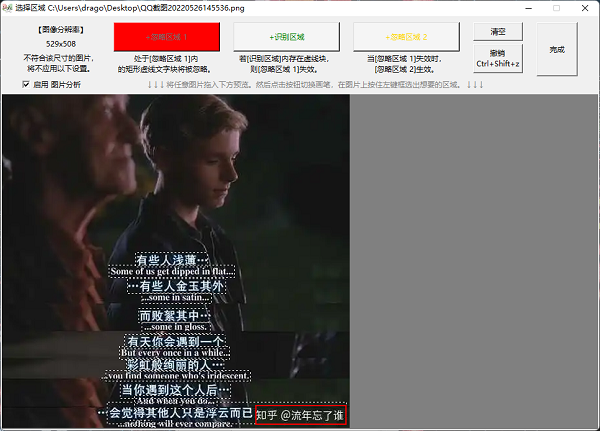 忽略区域功能描述:忽略区域1:正常情况下,忽略区域1中的文字不会输出。识别区:当识别区中存在文本时,忽略区域1的无效;也就是说,忽略区域1中的文本也将被输出。忽略区域2:当忽略区域1失效时,忽略区域2生效;也就是说,将输出区域1中的文本,而不输出区域2中的文本。然后点击开始任务,批量识别角色。从列表中可以看出内容基本确定。 忽略区域功能描述:忽略区域1:正常情况下,忽略区域1中的文字不会输出。识别区:当识别区中存在文本时,忽略区域1的无效;也就是说,忽略区域1中的文本也将被输出。忽略区域2:当忽略区域1失效时,忽略区域2生效;也就是说,将输出区域1中的文本,而不输出区域2中的文本。然后点击开始任务,批量识别角色。从列表中可以看出内容基本确定。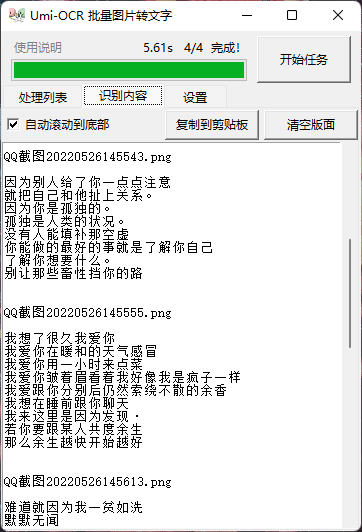 对比图中内容,中文内容基本正确。但部分英文内容可能是图片模糊的原因,识别中存在一些错误,所以尽量为识别出的图片选择清晰的大图。 对比图中内容,中文内容基本正确。但部分英文内容可能是图片模糊的原因,识别中存在一些错误,所以尽量为识别出的图片选择清晰的大图。
|
