SPSS中怎么使用分箱功能将连续数据离散化?
“分箱法”相信学过统计学的小伙伴们都不会陌生,它的主要作用就在于对噪音数据进行剔除,同时将连续型数据进行离散处理。在模型分析开始前,我们经常需要使用

“分箱法”相信学过统计学的小伙伴们都不会陌生,它的主要作用就在于对噪音数据进行剔除,同时将连续型数据进行离散处理。在模型分析开始前,我们经常需要使用到分箱法来处理和清洗数据。下面小编就带着大家一起学习一下吧!
操作方法:
图1是我们准备要分箱的数据,我们将对年龄列进行分箱,按照每10岁为一个标准进行分箱。
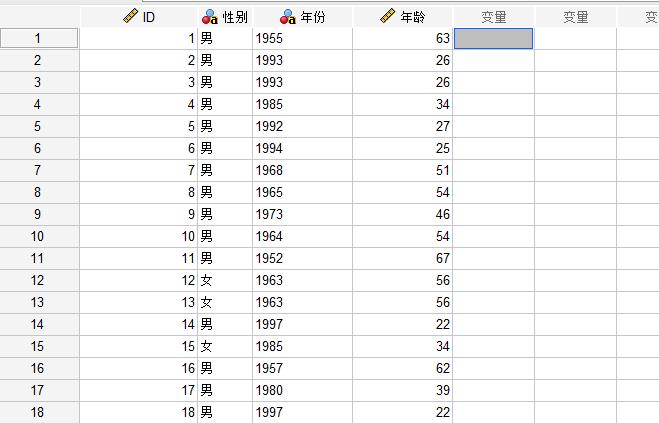 图1:要分箱的数据
图1:要分箱的数据点击“转换”中的“可视分箱”,进入分箱设置界面。
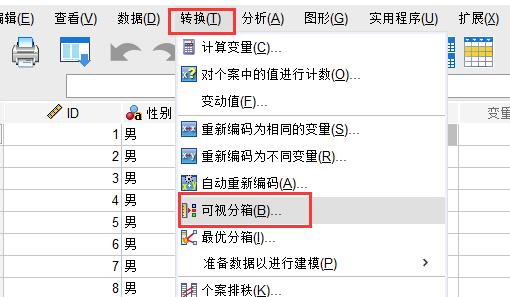 图2:可视分箱
图2:可视分箱将“年龄”拉入到“要分箱的变量”中,然后点击“继续”。
 图3:拉入要分箱的变量
图3:拉入要分箱的变量在图4所示界面,我们可以看到要扫描的个案数共34个,其中最大的变量值为67,最小为22,也就是说要分箱的数据年龄段在22到67岁之间。
我们在“分箱化变量”中,填入“年龄段”,作为一个之后新生成的变量,随后点击“生成分割点”按钮。
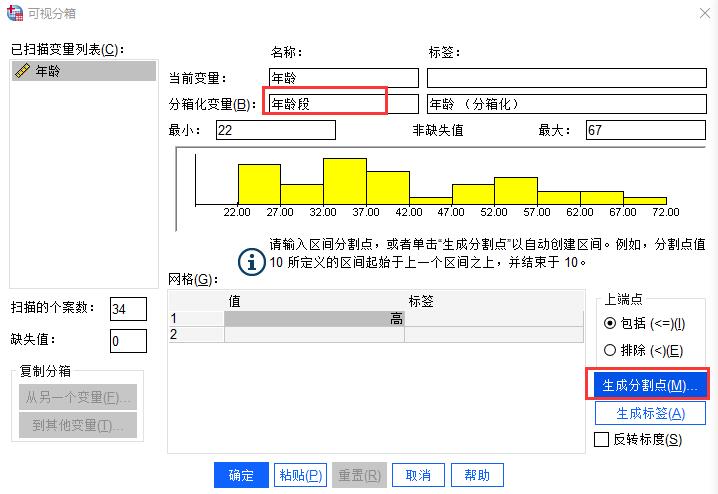 图4:分箱化变量
图4:分箱化变量按照我们的分箱目的,我们要每隔10岁分组一次,最小的年龄为22岁,则我们需要在第一个分割点位置填写“20”,然后在宽度填写“10”,此时点击键盘Tap键,SPSS会自动生成分割点数蔽明塞聪拼音:bì míng sè cōng释义:蔽遮;聪听觉灵敏;明看得清楚。蒙住眼睛不看,堵塞耳朵不听。指对外界事物不闻不问。出处:宋·曾巩《洪范传》夫然,故蔽明塞聪,而天下之情可坐而尽也。”示例:无的值为“5”,如图5所示。
这样子SPSS会自动帮我们将20到30、30到40、40到50、50到60、60到70的年龄段进行分组,一共5组。
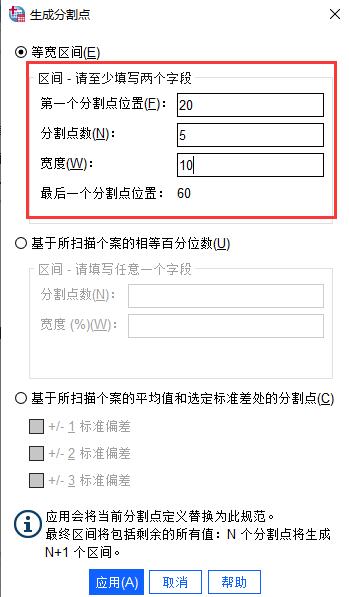 图5:生成分割点
图5:生成分割点点击“应用”按钮后,回到“可视分箱”界面中,我们可以在图6红框位置看到后续的分箱值,标签栏默认是空值,我们可以进行自定义填写,如设置20的分箱标签为2。
 图6:设置自定义标签
图6:设置自定义标签最后点击“确定”按钮,开始进行数据分箱,分箱后的新数据结果如图7所示,生成了新的“年龄段”列,数据也非常正确地进行了分箱,如年龄为27的那行数据,被正确地设置到了标签为2的分箱中。
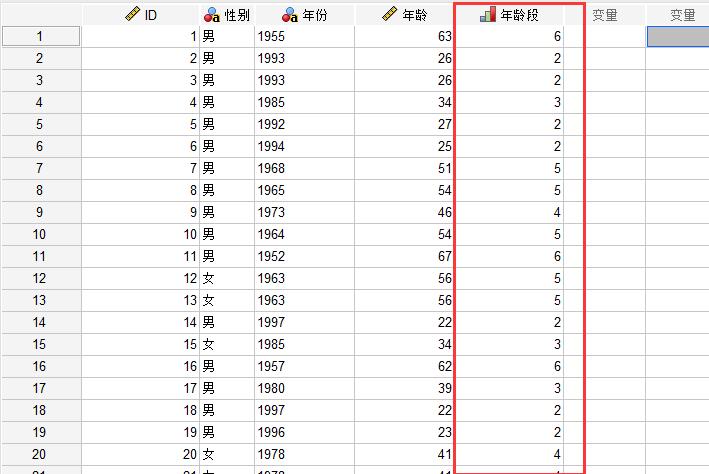 图7:分箱结果
图7:分箱结果以上就是使用IBM SPSS Statistic对演示数据中的年龄指标,按照每隔10岁的标准,进行分箱的全部教程,上述演示的是等距分箱,小伙伴也可以自己动手在IBM SPSS Statistic中尝试一下不等距分箱哦。















